某信读书无限下载以及导出epub书籍分析与实现
未经许可,不要转载
1 前言
wx读书app是个不错的产品,用了蛮久,但最近发现其广告越来越多,免费书籍越来越少,甚至曾经看完的书,再看都收费了。
于是就想把曾经看过的书籍导出保存。经过N天的研究,终于成功了。只要能全本下载的书籍,就可以导出。
该app大部分代码都是使用objective-c语言开发,该语言是比较灵活的动态语言,因此比较好逆向。
本文主要以技术分享为主,也顺便总结记录下经验,对于实验结果,只要肯钻研,相信大家都能实现自己的目标。
2 环境准备
硬件:Mac电脑(系统:MacOS 12.0.1)、 已越狱的iPhone6s(系统:iOS 13.6)
软件:XCode 13.1、 MonkeyDev(非越狱开发XCode插件)、 Sublime Text、 FinalShell(图形化ssh工具)、
Hopper Disassmembler、 某信读书.ipa(已脱壳,app版本:5.4.8)、真机调试的苹果证书
代码:QMUI框架(企鹅的)、SSZipArchive(zip解压缩开源代码)、从ipa中砸壳得到的头文件(非常有用,几乎等于看到了一半源代码)
关于越狱、ipa获取、ipa脱壳,非越狱开发调试等,大家可自行百度。
3 下载书籍分析,解除每月3次下载限制
只有完全下载的书籍,才能导出epub,这里也是为了更方便的导出epub做准备。
思路分析:
我们知道,每月下载多于3次就会有弹窗限制。
按照正常的程序逻辑,每次开始下载时,都应该去服务器端验证是否已超过3次。
这里确实验证了,但是仅仅验证了次数,并没有对下载的url进行处理。
也就是说如果对下载url限制的话,超过3次,访问下载的url就应该提示错误。这里并没有限制。
因此,就有个漏洞:只要我们绕过下载次数的验证,就能访问到下载的url了,就可以下载了。
那么为什么企鹅的工程师不在下载url上面进行验证呢?
这是因为:下载书籍的操作,与读书时加载书籍的逻辑是完全一样的。
具体逻辑是怎样的,我们放到后面章节。
现在我们的策略就很清晰了:绕过下载次数的限制。
如何绕过呢?有几种方法
比如修改验证次数请求的返回值,改为不超过3次。
每次开始下载时,直接跳过验证。
这里使用直接跳过验证。(因为验证请求的返回函数,没有hook到)
下面分析下载函数调用过程:新建WeReadDev MonkeyDev工程,拖入脱壳的ipa文件,导入砸壳得到的所有.h头文件(方便搜索),运行,打开下载页面。
3.1 分析下载按钮点击事件,即点击调用的函数
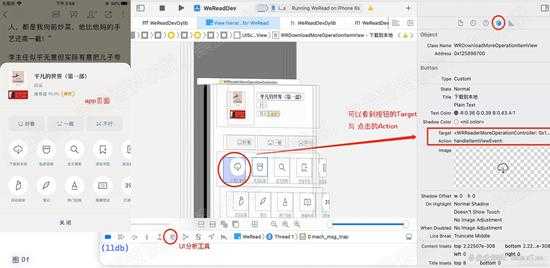
打开带有下载按钮的页面后,使用XCode的UI界面分析工具,分析下载按钮以及页面所在的控制器(MVC中的C)
选中【下载到本地】按钮,然后右侧导航栏,选择倒数第2个工具图标,查看按钮的属性,我们主要看按钮事件名以及所属的类名,
可以看到按钮事件的target在 WRReaderMoreOperationController 中,事件方法为 handleItemViewEvent
如下图:
d01.jpg
d01
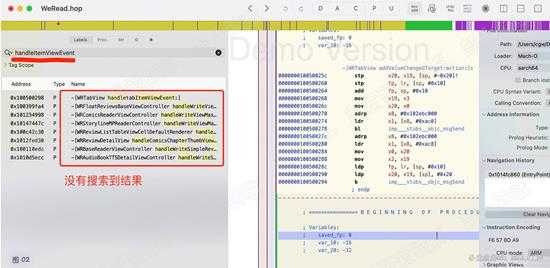
接下来,我们按照点击的函数去顺腾摸瓜,找到下载的真正函数。因此打开Hopper,把xxx.ipa拖进去,搜索handleItemViewEvent方法。
很不幸,hopper中,居然没有该函数。如下图:
d02.jpg
d02
还记得砸壳出的所有头文件吗?我们去头文件中,看看有没有handleItemViewEvent。依然没有。
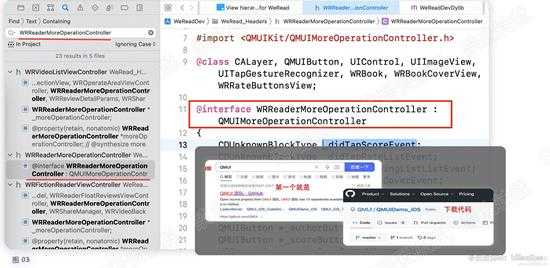
那我们搜下按钮的target类即:WRReaderMoreOperationController
可以看到该类是存在的,那么为什么按钮点击的方法却没有呢,原因:点击事件应该是父类的方法,因此,我们看看它的父类 QMUIMoreOperationController
看着名字就感觉很奇怪,WR我们可以猜测代表WeRead, QMUI开头的应该就是通用的类库了,大厂都会封自己的基本类库,不奇怪。如下图:
d03.jpg
d03
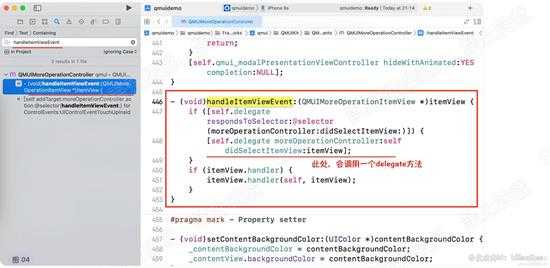
那么该如何继续分析呢? 大厂的基本类库是开源的,因此我们直接拿来源代码看看,百度QMUI,下载下来。xCode打开QMUI的代码,我们全局搜索handleItemViewEvent
在类QMUIMoreOperationController中,搜索到了该方法,在该方法内部调用了一个delegate和一个block, 在本读书app中,使用的是代{过}{滤}理,
也就是实现了方法:didSelectItemView。 如下图:
d04.jpg
d04
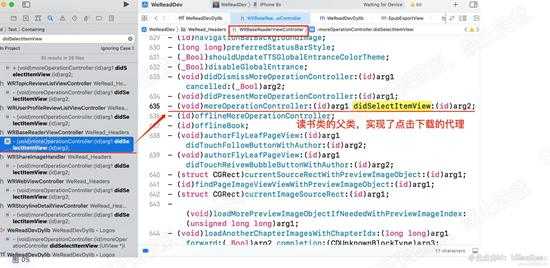
在我们的项目中,全局搜索didSelectItemView,可以看到很多类都实现了此代{过}{滤}理方法。那么点击下载后,具体是哪个类调用了该方法呢。
其实是类:WRReaderViewController ,它的父类WRBaseReaderViewController实现了该方法。如下图:
WRReaderViewController,该类就是正在读书的页面的真正的控制器,也就是说,正在读书的页面逻辑操作,基本都由此类控制(若代码遵循MVC原则的话)。
后面会分析为何该类为读书页面的控制类。
d05.jpg
d05
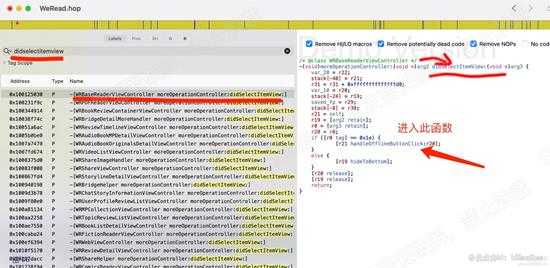
现在我们知道在那个类调用了点击下载的方法了,接下来继续寻找真正下载的函数。在hopper中,全局搜索didSelectItemView,可以发现有很多个。
我们定位到 WRBaseReaderViewController 该类中的didSelectItemView方法。(因为该类是读书控制类的父类)。如下图:
d06.jpg
d06
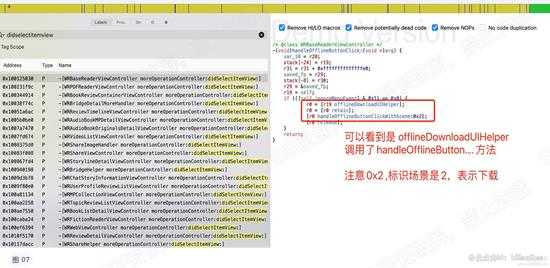
可以看到内部调用了 handleOfflineButtonclick 方法。双击进入该方法。如下图:
d07.jpg
d07
可以看到内部调用了 handleOfflineButtonClickWithScene 方法,该方法由offlineDownloadUIHelper 获取到的对象调用。双击跳转进入:
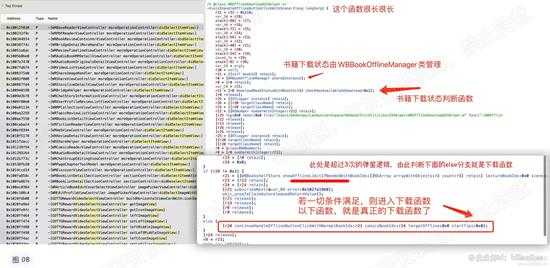
该方法很长,我们只看关键部分,这里有3个主要部分: 如下图。
下载状态函数: 该方法用来判断是否已下载本书。这里先有个大概印象,之后需要用到。
downloadBookStatusWithBookId:(id)arg1 checkHasAvailableUnDownload:(Bool)arg2
判断本月下载是否多于3次:这里是需要跳过的地方。
下载函数:使用此方法下载书籍。
continueHandleOfflineRuttonClickWithNormalBookIds: comicsBookIds: targetOffline: startTips:
d08.jpg
d08
至此,我们已经找到需要跳过的地方,以及下载的函数了。接下来开始实现无限下载。
3.2 根据分析的结果,实现无限下载
经过上面分析,我们清楚了下载点击时函数调用关系。那么如何跳过3次限制呢?
这里我们用如下思路:
当点击按钮时,直接调用下载书籍的函数。(去掉中间的各个过程,这就绕过次数验证了)
首先hook点击按钮时会调用的函数,经过上面分析,会调用很多函数。hook哪一个呢?
这里hook 此函数:handleOfflineButtonClickWithScene。
为什么hook它,因为该函数所属的实例对象,调用了真正的下载函数。也就是真正的下载函数与本函数 是属于同一个类的方法。
在分析中,我们知道该方法的实例对象 是由 offlineDownloadUIHelper 这个东西返回的。我们全局搜索下,看看它是啥。如下图:
可以看到,其是WROfflineDownloadUIHelper类的对象,也就是说下载函数在WROfflineDownloadUIHelper类中。
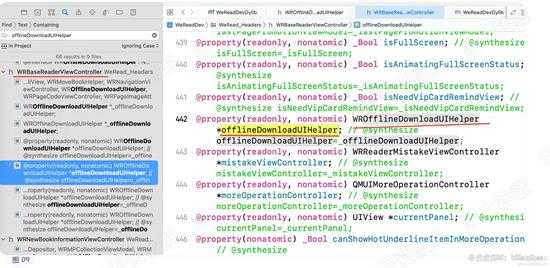
d09.jpg
d09
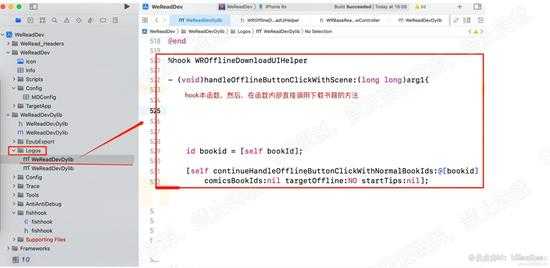
接下来,直接hook WROfflineDownloadUIHelper类的handleOfflineButtonClickWithScene方法,
并且在hook方法内部,直接调用下载函数
continueHandleOfflineRuttonClickWithNormalBookIds: comicsBookIds: targetOffline: startTips:
关于参数的传递:
第一个 NormalBookIds:显然是普通书籍的id,可以从本实例得到。
第二个 comicsBookIds:猜测是漫画书的id,忽略漫画,所以全部传空。
第三个 targetOffline:传NO,根据Hooper中的反汇编代码,可知传NO
第四个 startTips: 猜测是开始时的提示,这里忽略。传空。
这里使用logos语法进行hook,请看代码:如下图
d10.jpg
d10
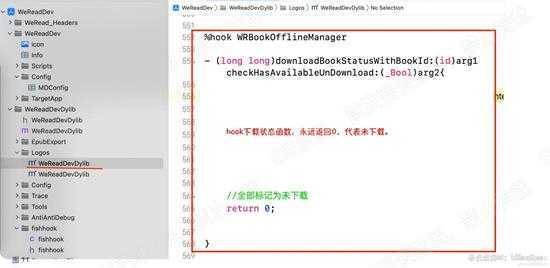
至此,下载的次数就被去掉了,就可以无数次下载了。不过,这里我们还要做一件事,那就是hook下载状态。让所有书籍都可以重新下载。
之所以如此是因为:导出epub书籍,我们使用的是下载的zip文件包的内容。
而微信读书的下载逻辑是:下载某个章节的zip包,然后解压数据并加密后,拷贝到该书籍的缓存目录,清空zip文件。
因此,我们每次获取zip包,必须重新下载。下面请看hook下载状态函数,如下图:
d11.jpg
d11
至此,就完全可以无限次、重复的下载了。
4 书籍的文件结构分析
想导出书籍,我们必须弄清楚,书籍在本地是如何存放的,其数据结构是什么。了解了之后,才能知道以何种方式导出。因此本过程是必须的。
4.1 查看书籍的缓存文件
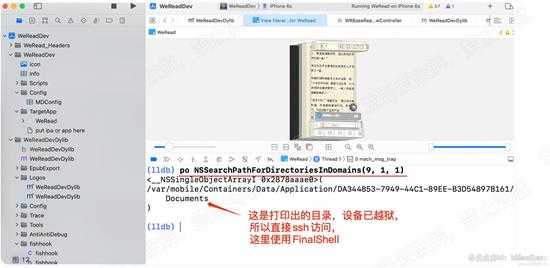
因为iOS系统有沙盒机制,应用都有自己的缓存目录。因此在app运行时,我们直接使用XCode打印出沙盒的路径。就可以看到App缓存在本地的所有文件内容了。
启动XCode运行我们的WeReadDev项目,app启动后,随意打开一本书,然后点击UI分析工具,这样程序会暂停,我么可以使用XCode中集成的lldb调试器打印数据。
打印出目录:/var/mobile/Containers/Data/Application/DA344853-7949-44C1-89EE-B3D54897B161/Documents 如下图
d12.jpg
d12
使用FinalShell连接设备,查看文件。有很多文件夹,最后发现发现个Books文件夹,里面是一对数字文件夹。随意进入个,内部是一堆html文件。
/var/mobile/Containers/Data/Application/DA344853-7949-44C1-89EE-B3D54897B161/Library/254802774/Books
由此,可以猜测,此处就是书籍缓存目录了。只是书籍数据是加密过的。
如下图
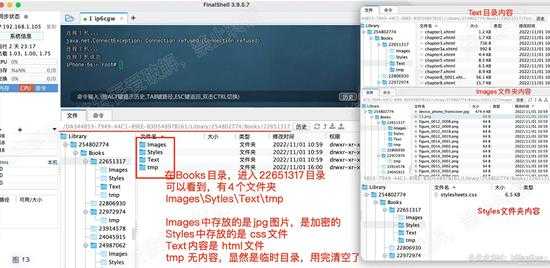
d13.jpg
d13
4.2 解密缓存文件
我们需要解密出缓存文件内容,然后根据内容,看如何导出文件。如何解密呢?
根据经验,直接在项目中,全局搜索decrypt关键字。会发现很多相关的函数。
依据函数名以及所属的类,这里我们直接定位到 所属于 WREpubFileManager 类的以下方法:
- (id)decryptContentsOfFile:(id)arg1 forBookId:(id)arg2; 如下图:
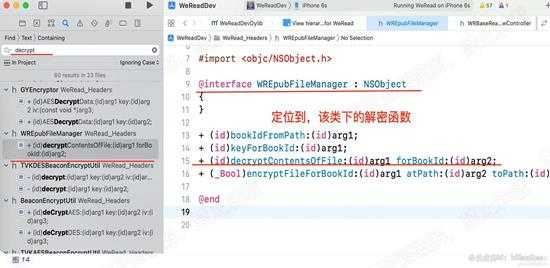
d14.jpg
d14
接下来,hook该方法,并打印日志,然后运行app,打开新的书籍,看是否会打印日志。
经过测试,每次加载新的章节,就会调用该方法解密.通过参数的值,可以确定解密的就是缓存的文件。如下图:
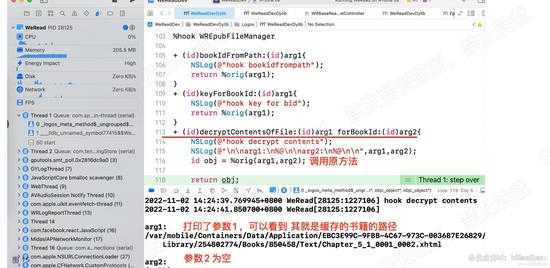
d15.jpg
d15
该函数的返回值,应该就是解密后的数据。接下来就验证下数据。
断点至该函数结束完成,打印返回值,得知类型是NSData,二进制数据流。我们直接把它写入本地文件,然后导出查看内容。
写了个保存文件函数,打印了导出路径:如下图
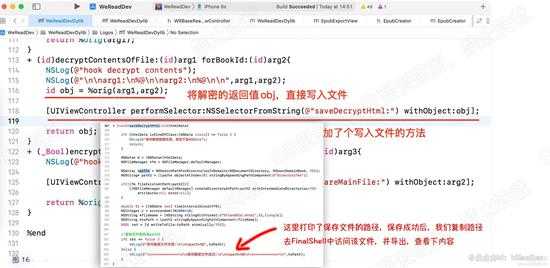
d16.jpg
d16
用FinalShell访问路径,导出文件,然后查看其内容。可以发现,html文本内容就是书籍的内容。如下图:
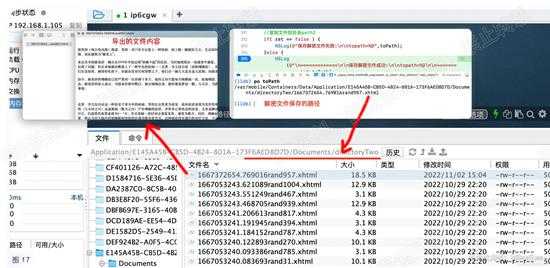
d17.jpg
d17
由此,我们就可以拿到解密的缓存文件了。
这里要注意下:加密的所有文件都是通过此函数来进行解密的,包括图片、css文件等。
4.3 分析文件结构以及书籍加载逻辑
书籍已经解密了,接下来简要看下文件结构。
在书籍的缓存的Books目录下,有很多数字的文件夹,每个数字目录代表一本书,数字就是书的ID(解析过程略过)。
我们来看下某书籍下的目录:有4个文件夹Images、Styles、Text、Tmp 。
这里直接上结论,书籍内容主要由Text内的html文件提供,另外的Images和Styles提供html需要的资源。Tmp临时目录,忽略。
书籍内容由html提供,可以确定,这是可以组装成epub文件导出的。
因此,我们只要想办法把 Images、Styles、Text这3个文件夹的内容组合到一起,导出即可。
但是因为 Text文件夹内,有许多章节的html,无法确定章节的顺序,以及索引等数据,因此直接使用解密的缓存文件导出epub,可能会造成书籍数据混乱。
所以要想准确的组装数据,还需要找到带有章节索引信息的的数据。这就是下面4.4部分需要描述的内容。
继续之前,先分析下书籍的加载逻辑。
经测试得知。阅读图书时,书籍内容的加载逻辑是:
a、每次加载一个zip数据包,该数据包中包含不定章节内容,可能含有1个章节,也可能多个。
b、获取到zip数据包后,解压数据,此时的数据是未加密的。然后对数据加密,缓存至书籍的缓存目录。
c、读书时,先从本地缓存目录查找,若不存在就去下载zip包。
注意:一开始打开图书时,会预先加载部分zip数据。
下载逻辑与阅读时的加载逻辑类似。
因为点击了下载按钮后,也是先去本地缓存目录看有没有,若没有就下载zip,然后加密数据,缓存。
因此下载也是一个zip,一个zip的获取。
也就是说 下载其实就是 一起把书籍所有章节全部缓存到本地。
与你直接看完一本书,是一个道理。
4.4 寻找书籍的源文件(下载的zip文件)
zip文件是猜测的,因为数据要在互联网上传输,一定需要压缩。还有epub文件本身就是zip的压缩方式。
起初的思路是直接hook解压的方法,因为zip一定需要解压,但是试了几个,都没有找到解压的函数。
后来又想到,解压文件一定会用到写入文件的方法,因此,我们hook写入文件的方法。看是否可以找到解压zip的函数。
如下图,我hook了NSData的所有写入文件的方法,果然写入文件的操作,都被抓到了。同时还有个意外收获。
就在某个文件写入前,有一个函数吸引了注意,如下:
[WRBookNetwork processEpubZipAtPath:book:chapterUids:chaptersStr:isFromReview:]
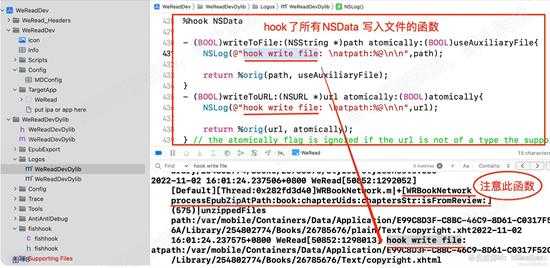
d18.jpg
d18
看名字 processEpubZipAtPath, 有epub 有zip,猜测就是源文件了。因此在头文件搜索,果然搜到了。
这里去hopper中,看了下该函数的伪代码,发现其内部确实是对zip进行了解压操作,然后加密文件,拷贝至书籍目录。
在hopper中,可以看到解压用的是SSZipArchive三方类库。稍后我们解压和导出epub时也就用它了。
直接hook该函数,看看传进来的参数都是什么。运行,断点在该hook的函数,打印参数:
可以知道,第一个参数就是zip文件路径,第二个参数是 WRBook对象。使用FinalShell访问路径,导出文件,改为zip打开。如下图:
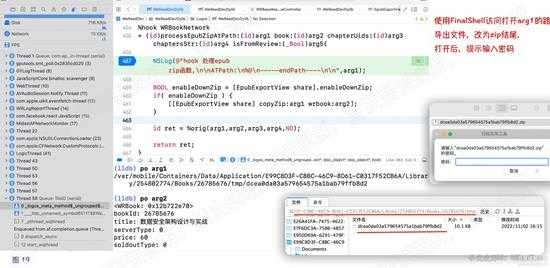
d19.jpg
d19
关于密码的获取,是在hopper中发现的,因为这里要解压文件,所以密码肯定在相关的参数中,这里直接公布答案:密码是WRBook类的epubPassword方法返回的。
因此,我们直接在XCode刚才的断点处,直接执行代码: [((WRBook*)arg2) epubPassword] ,可以看到返回了一个字符串:hi7GPj12y
使用该值,成功的解压了刚才的zip,可以看到,zip内的文件结构与书籍缓存的类似,但是多了一个 info.txt 文件,如下图:
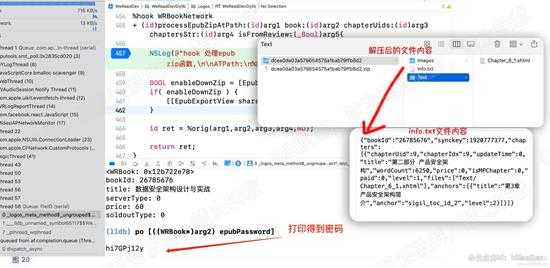
d20.jpg
d20
从 info.txt 的文件内容就可以确定,该文件就是html文件的索引信息(相当于书籍的目录),有了索引信息,有了书籍内容,就可以完整的导出书籍了。
4.5 小结
我们重新梳理下书籍的加载(下载)逻辑。
a、点击下载按钮
b、去本地缓存目录查找是否存在。
c、不存在,开始下载zip
d、解压zip文件到临时目录
c、加密解压后的文件,缓存至书籍目录(不包括索引文件)
e、清空临时目录内容
至此,我们已经完全清楚书籍文件的来源,结构,加解密过程。那么如何导出epub文件呢?
思路如下:
在步骤d中,我们拷贝zip文件以及密码到指定目录,
然后把书籍的所有的zip数据解压合并,根据info.txt创建索引信息,组装成epub格式,导出。
5 导出epub
我们知道书籍的存储结构了,也知道缓存文件在哪,那么我们只要将书籍的所有源文件整合到一起,然后保存文件即可
5.1 epub文件格式概述
由于我们想组装成epub,需要先了解下其格式。
a、mimetype
每一个epub电子书均包含一个名为mimtype的文件,内容固定为:application/epub+zip,用以表示是epub的文件格式。
b、META-INF(文件夹,包含一个文件container.xml)
用于存放容器信息,主要用于告诉阅读器,电子书的根文件(rootfile)的路径和打开格式,内容可以一般固定不变,除非改变了OEBPS目录名。
c、OEBPS(文件夹,包含images文件夹、很多html文件、css文件和content.opf文件等)
OEPBS目录用于存放OPF文档、CSS文件、NCX文档。
OPF文档是epub的核心文件,且是一个标准的xml文件,依据OPF规范,此文件的根元素为<package>由五部分组成:<metadata>、<mainfest>、<spine toc="ncx">、<guide>、<tour>
NCX文件是epub电子书的又一个核心文件,用于制作电子书的目录,其文件的命名通常为toc.ncx。ncx文件也是一个xml文件。ncx代表“Navigation Center eXtended”,意思大致就是导航文件,这个文件与目录有直接的关系。
mimetype和META-INF的内容,我们固定写死,不用修改。
我们要修改的文件主要是 opf和ncx的内容。
下面请看完整的Epub文件结构示意图:

d21.jpg
d21
5.2 在页面上添加导出按钮
我们可以在下载书籍时,拿到书籍的所有章节的zip文件,但我们还需要一个导出zip的入口。
因此我们就在书籍页面的右上角添加一个export按钮。
添加方式是:hook 读书控制器类WRReaderViewController的viewDidAppear方法,当该方法调用时,在页面上添加一个按钮。
新建类 EpubExportView ,写成单例模式,添加按钮以及导出的事件都在此类中完成。看下效果图。

d22.jpg
d22
5.3 下载书籍时,保存所有章节的zip包
这里其实就比较简单了,在我们hook的processZip的函数中,复制zip文件以及密码进行保存。如下图:
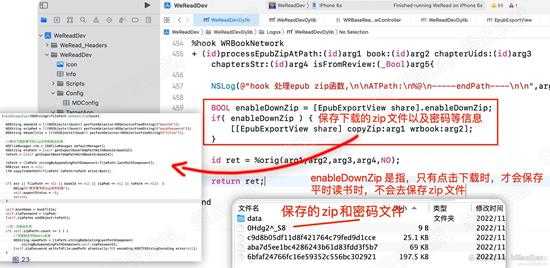
d23.jpg
d23
5.4 构建epub书籍文件的内容
首先解压所有的zip文件,并移动到指定data目录。
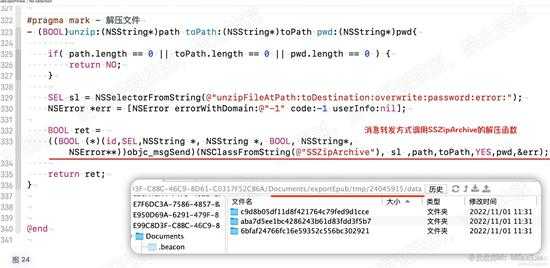
前文提到在app内使用了三方的解压工具SSZipArchive,因此我们也使用它。去网上找到其代码找到函数原型,动态调用。
我们肯定没办法直接调用原app内的函数,缺少声明,编译器会报错。又因为解压的函数参数过多,不方便使用oc的动态调用方法。
因此,这里直接使用oc消息转发机制,使用c语言的调用方式。请看下图:
d24.jpg
d24
组装epub内容
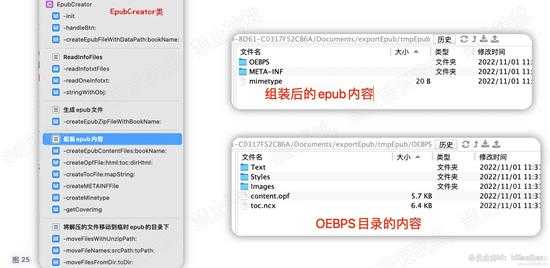
可以看到,我们已经将所有文件都解压到data目录了。
因为每个zip包的目录下,都有3个文件夹和1个info.txt文件,因此我们需要把多个zip中的各文件夹合并到一起。
在合并过程中,info.txt文件不需要进行操作,仅仅记录下各个info文件所在的路径。稍后会根据所有info.txt创建epub内容。
然后,再将这3个文件夹移动到epub的OEBPS目录中。
移动完成后,根据info.txt文件创建ncx和opf文件。
这里我写了一个EpubCreator类来进行操作。如下图:
d25.jpg
d25
5.5 导出epub文件
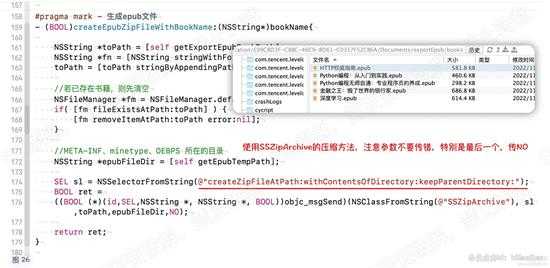
内容组装完成,接下来压缩导出文件。
这里直接使用SSZipArchive类的压缩方法,直接将准备好的epub内容进行压缩成epub文件。
d26.jpg
d26
这里是导出到了指定目录,那么如果是在非越狱的机器上,如何查看导出的书籍呢?
答案:在XCode中,公开文档目录,通过文件App访问。
过程就不赘述了,看下效果图吧。
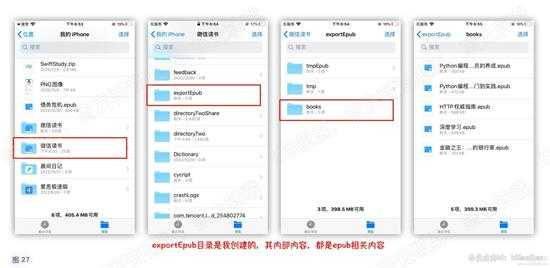
d27.jpg
d27
5.6 小结
每次下载书籍前,最好清空下原有缓存,避免个别章节没有下到。
导出的过程,基本上就是正向开发。没有什么难点,相对的难点可能是 解压和压缩的代码调用了。
6 总结
其实,很久之前就砸壳了该app,逆向了几张壁纸,也解密了文章缓存,但对于导出还是耗费了些时间。
特别是对于书籍源文件的获取。以及还原书籍下载的逻辑,也是耗费了不少脑细胞。
希望本文对于技术学习的朋友可以有所帮助。
因本人水平有限,若有错误之处,欢迎指出!谢谢大家!
未经许可,禁止转载
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
P70系列延期,华为新旗舰将在下月发布
3月20日消息,近期博主@数码闲聊站 透露,原定三月份发布的华为新旗舰P70系列延期发布,预计4月份上市。
而博主@定焦数码 爆料,华为的P70系列在定位上已经超过了Mate60,成为了重要的旗舰系列之一。它肩负着重返影像领域顶尖的使命。那么这次P70会带来哪些令人惊艳的创新呢?
根据目前爆料的消息来看,华为P70系列将推出三个版本,其中P70和P70 Pro采用了三角形的摄像头模组设计,而P70 Art则采用了与上一代P60 Art相似的不规则形状设计。这样的外观是否好看见仁见智,但辨识度绝对拉满。
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]